Asynchronous Inserts (async_insert)
Inserting data into ClickHouse in large batches is a best practice. It saves compute cycles and disk I/O, and therefore it saves money. If your usecase allows you to batch your inserts external to ClickHouse, then that is one option. If you would like ClickHouse to create the batches, then you can use the asynchronous INSERT mode described here.
Use asynchronous inserts as an alternative to both batching data on the client-side and keeping the insert rate at around one insert query per second by enabling the async_insert setting. This causes ClickHouse to handle the batching on the server-side.
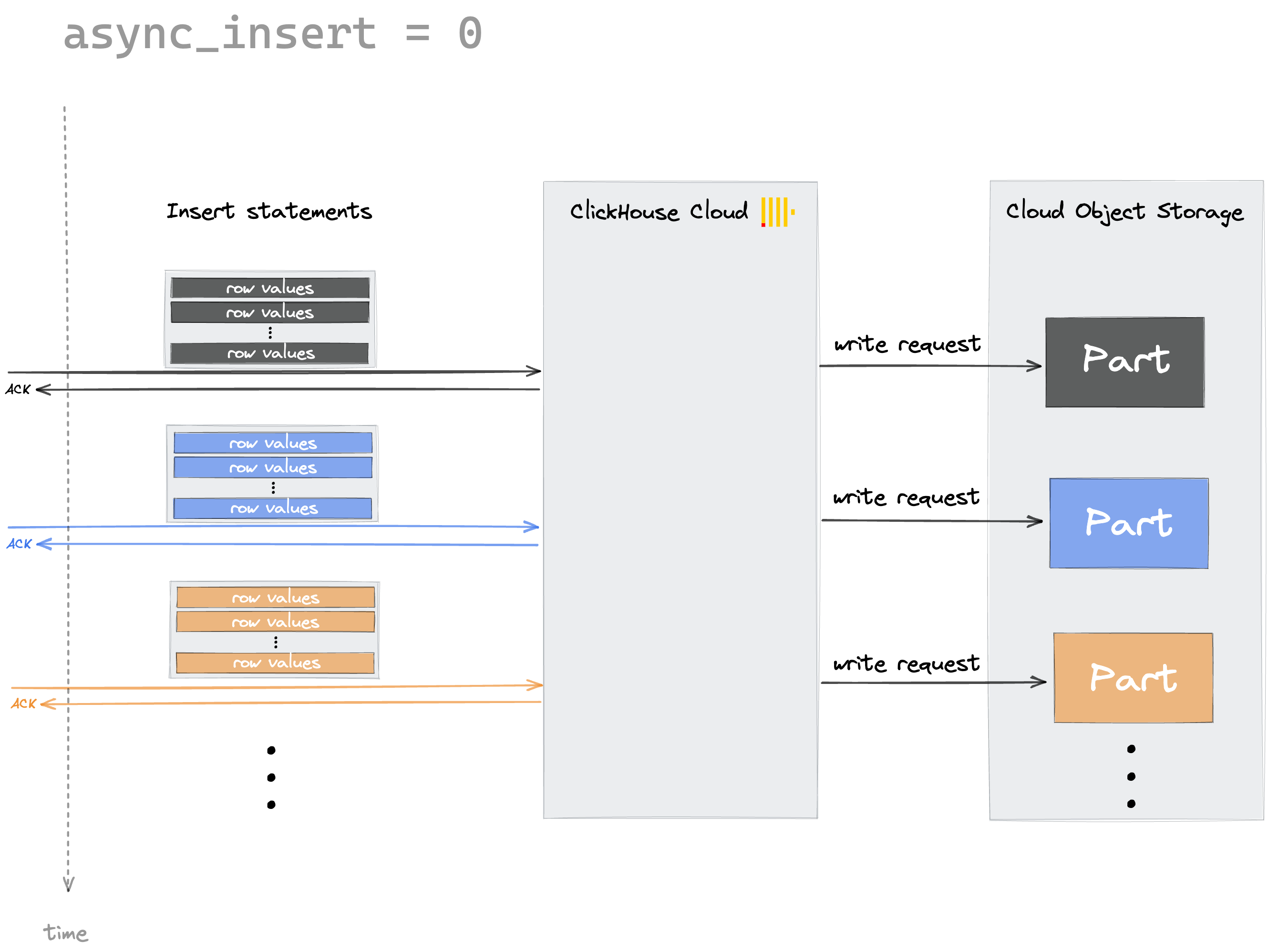
By default, ClickHouse is writing data synchronously. Each insert sent to ClickHouse causes ClickHouse to immediately create a part containing the data from the insert. This is the default behavior when the async_insert setting is set to its default value of 0:
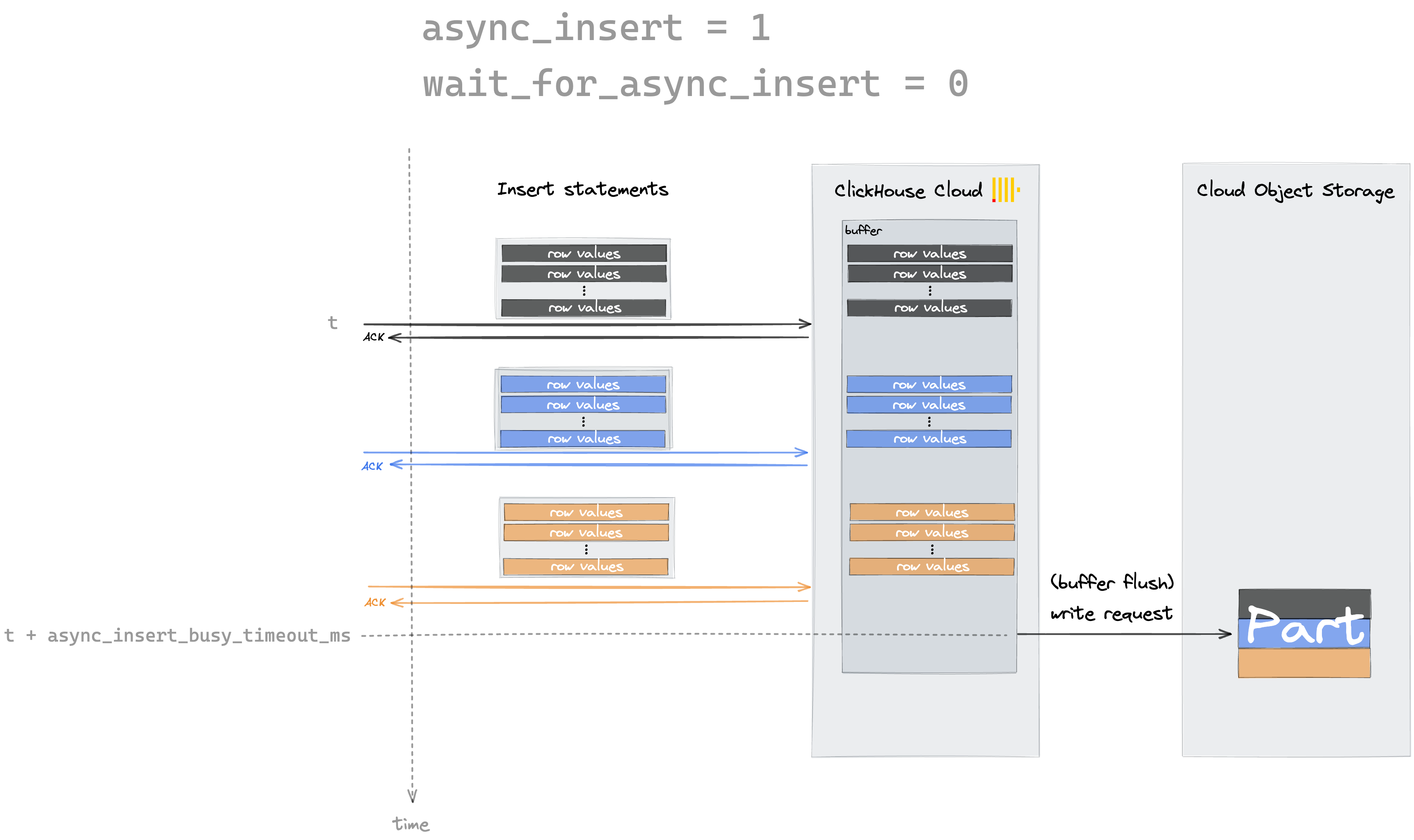
By setting async_insert to 1, ClickHouse first stores the incoming inserts into an in-memory buffer before flushing them regularly to disk.
There are two possible conditions that can cause ClickHouse to flush the buffer to disk:
- buffer size has reached N bytes in size (N is configurable via async_insert_max_data_size)
- at least N ms has passed since the last buffer flush (N is configurable via async_insert_busy_timeout_ms)
Everytime any of the conditions above are met, ClickHouse will flush its in-memory buffer to disk.
Your data is available for read queries once the data is written to a part on storage. Keep this in mind for when you want to modify the async_insert_busy_timeout_ms (set as 1 second by default) or the async_insert_max_data_size (set as 10 MiB by default) settings.
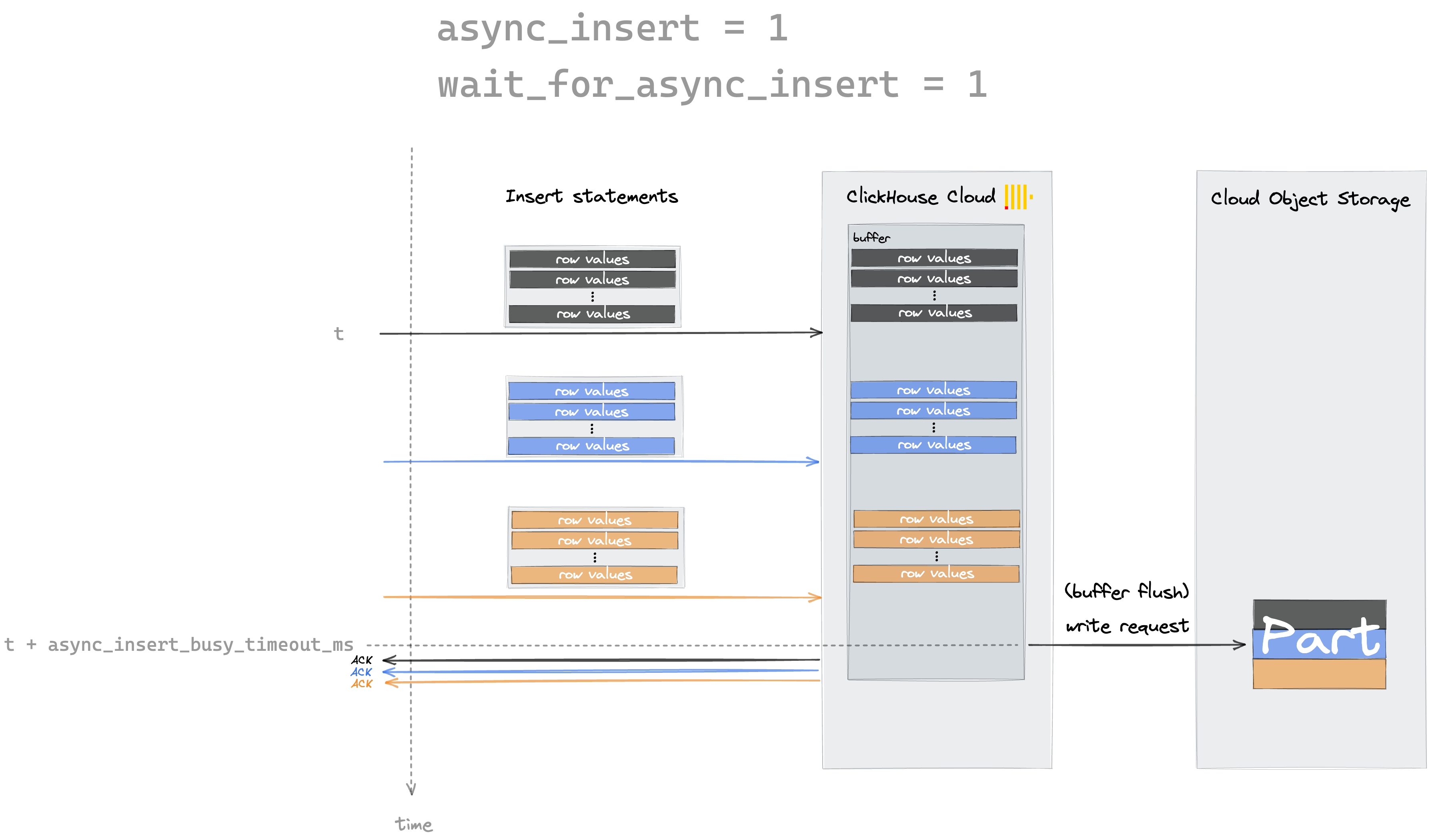
With the wait_for_async_insert setting, you can configure if you want an insert statement to return with an acknowledgment either immediately after the data got inserted into the buffer (wait_for_async_insert = 0) or by default, after the data got written to a part after flushing from buffer (wait_for_async_insert = 1).
The following two diagrams illustrate the two settings for async_insert and wait_for_async_insert:
Enabling asynchronous inserts
Asynchronous inserts can be enabled for a particular user, or for a specific query:
Enabling asynchronous inserts at the user level. This example uses the user
default, if you create a different user then substitute that username:ALTER USER default SETTINGS async_insert = 1You can specify the asynchronous insert settings by using the SETTINGS clause of insert queries:
INSERT INTO YourTable SETTINGS async_insert=1, wait_for_async_insert=1 VALUES (...)You can also specify asynchronous insert settings as connection parameters when using a ClickHouse programming language client.
As an example, this is how you can do that within a JDBC connection string when you use the ClickHouse Java JDBC driver for connecting to ClickHouse Cloud :
"jdbc:ch://HOST.clickhouse.cloud:8443/?user=default&password=PASSWORD&ssl=true&custom_http_params=async_insert=1,wait_for_async_insert=1"Our strong recommendation is to use async_insert=1,wait_for_async_insert=1 if using asynchronous inserts. Using wait_for_async_insert=0 is very risky because your INSERT client may not be aware if there are errors, and also can cause potential overload if your client continues to write quickly in a situation where the ClickHouse server needs to slow down the writes and create some backpressure in order to ensure reliability of the service.
Manual batching (see section above)) has the advantage that it supports the built-in automatic deduplication of table data if (exactly) the same insert statement is sent multiple times to ClickHouse Cloud, for example, because of an automatic retry in client software because of some temporary network connection issues.