Materialized View
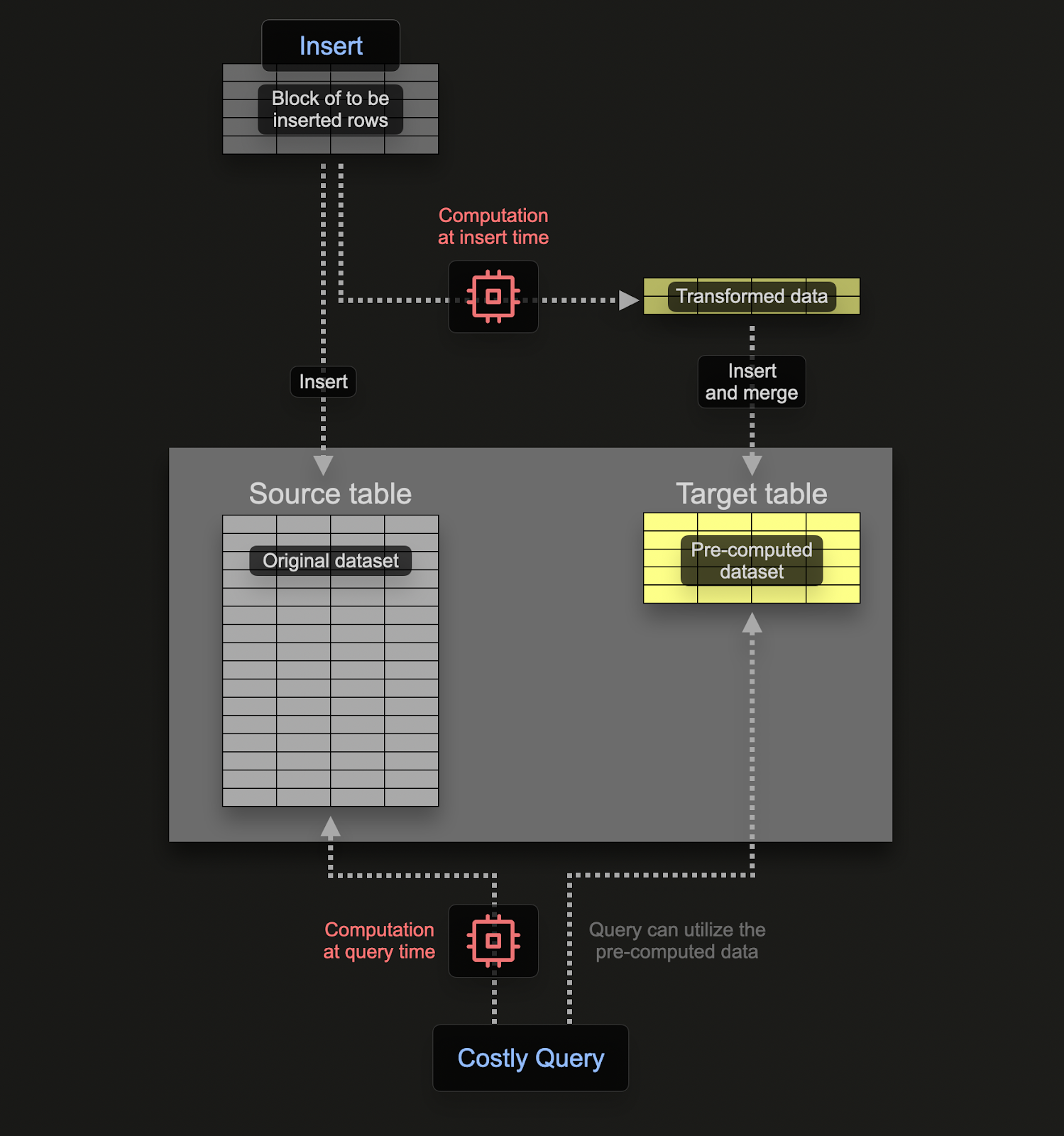
Materialized views allow users to shift the cost of computation from query time to insert time, resulting in faster SELECT queries.
Unlike in transactional databases like Postgres, a ClickHouse materialized view is just a trigger that runs a query on blocks of data as they are inserted into a table. The result of this query is inserted into a second "target" table. Should more rows be inserted, results will again be sent to the target table where the intermediate results will be updated and merged. This merged result is the equivalent of running the query over all of the original data.
The principal motivation for materialized views is that the results inserted into the target table represent the results of an aggregation, filtering, or transformation on rows. These results will often be a smaller representation of the original data (a partial sketch in the case of aggregations). This, along with the resulting query for reading the results from the target table being simple, ensures query times are faster than if the same computation was performed on the original data, shifting computation (and thus query latency) from query time to insert time.
Materialized views in ClickHouse are updated in real time as data flows into the table they are based on, functioning more like continually updating indexes. This is in contrast to other databases where materialized views are typically static snapshots of a query that must be refreshed (similar to ClickHouse refreshable materialized views).
Example
Suppose we want to obtain the number of up and down votes per day for a post.
This is a reasonably simple query in ClickHouse thanks to the toStartOfDay function:
SELECT toStartOfDay(CreationDate) AS day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY day
ORDER BY day ASC
LIMIT 10
┌─────────────────day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 00:00:00 │ 6 │ 0 │
│ 2008-08-01 00:00:00 │ 182 │ 50 │
│ 2008-08-02 00:00:00 │ 436 │ 107 │
│ 2008-08-03 00:00:00 │ 564 │ 100 │
│ 2008-08-04 00:00:00 │ 1306 │ 259 │
│ 2008-08-05 00:00:00 │ 1368 │ 269 │
│ 2008-08-06 00:00:00 │ 1701 │ 211 │
│ 2008-08-07 00:00:00 │ 1544 │ 211 │
│ 2008-08-08 00:00:00 │ 1241 │ 212 │
│ 2008-08-09 00:00:00 │ 576 │ 46 │
└─────────────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.133 sec. Processed 238.98 million rows, 2.15 GB (1.79 billion rows/s., 16.14 GB/s.)
Peak memory usage: 363.22 MiB.
This query is already fast thanks to ClickHouse, but can we do better?
If we want to compute this at insert time using a materialized view, we need a table to receive the results. This table should only keep 1 row per day. If an update is received for an existing day, the other columns should be merged into the existing day's row. For this merge of incremental states to happen, partial states must be stored for the other columns.
This requires a special engine type in ClickHouse: the SummingMergeTree. This replaces all the rows with the same ordering key with one row which contains summed values for the numeric columns. The following table will merge any rows with the same date, summing any numerical columns:
CREATE TABLE up_down_votes_per_day
(
`Day` Date,
`UpVotes` UInt32,
`DownVotes` UInt32
)
ENGINE = SummingMergeTree
ORDER BY Day
To demonstrate our materialized view, assume our votes table is empty and have yet to receive any data. Our materialized view performs the above SELECT on data inserted into votes, with the results sent to up_down_votes_per_day:
CREATE MATERIALIZED VIEW up_down_votes_per_day_mv TO up_down_votes_per_day AS
SELECT toStartOfDay(CreationDate)::Date AS Day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY Day
The TO clause here is key, denoting where results will be sent to i.e. up_down_votes_per_day.
We can repopulate our votes table from our earlier insert:
INSERT INTO votes SELECT toUInt32(Id) AS Id, toInt32(PostId) AS PostId, VoteTypeId, CreationDate, UserId, BountyAmount
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes.parquet')
0 rows in set. Elapsed: 111.964 sec. Processed 477.97 million rows, 3.89 GB (4.27 million rows/s., 34.71 MB/s.)
Peak memory usage: 283.49 MiB.
On completion, we can confirm the size of our up_down_votes_per_day - we should have 1 row per day:
SELECT count()
FROM up_down_votes_per_day
FINAL
┌─count()─┐
│ 5723 │
└─────────┘
We've effectively reduced the number of rows here from 238 million (in votes) to 5000 by storing the result of our query. What's key here, however, is that if new votes are inserted into the votes table, new values will be sent to the up_down_votes_per_day for their respective day where they will be automatically merged asynchronously in the background - keeping only one row per day. up_down_votes_per_day will thus always be both small and up-to-date.
Since the merging of rows is asynchronous, there may be more than one vote per day when a user queries. To ensure any outstanding rows are merged at query time, we have two options:
- Use the
FINALmodifier on the table name. We did this for the count query above. - Aggregate by the ordering key used in our final table i.e.
CreationDateand sum the metrics. Typically this is more efficient and flexible (the table can be used for other things), but the former can be simpler for some queries. We show both below:
SELECT
Day,
UpVotes,
DownVotes
FROM up_down_votes_per_day
FINAL
ORDER BY Day ASC
LIMIT 10
10 rows in set. Elapsed: 0.004 sec. Processed 8.97 thousand rows, 89.68 KB (2.09 million rows/s., 20.89 MB/s.)
Peak memory usage: 289.75 KiB.
SELECT Day, sum(UpVotes) AS UpVotes, sum(DownVotes) AS DownVotes
FROM up_down_votes_per_day
GROUP BY Day
ORDER BY Day ASC
LIMIT 10
┌────────Day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 │ 6 │ 0 │
│ 2008-08-01 │ 182 │ 50 │
│ 2008-08-02 │ 436 │ 107 │
│ 2008-08-03 │ 564 │ 100 │
│ 2008-08-04 │ 1306 │ 259 │
│ 2008-08-05 │ 1368 │ 269 │
│ 2008-08-06 │ 1701 │ 211 │
│ 2008-08-07 │ 1544 │ 211 │
│ 2008-08-08 │ 1241 │ 212 │
│ 2008-08-09 │ 576 │ 46 │
└────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.010 sec. Processed 8.97 thousand rows, 89.68 KB (907.32 thousand rows/s., 9.07 MB/s.)
Peak memory usage: 567.61 KiB.
This has sped up our query from 0.133s to 0.004s – an over 25x improvement!
A more complex example
The above example uses materialized views to compute and maintain two sums per day. Sums represent the simplest form of aggregation to maintain partial states for - we can just add new values to existing values when they arrive. However, ClickHouse materialized views can be used for any aggregation type.
Suppose we wish to compute some statistics for posts for each day: the 99.9th percentile for the Score and an average of the CommentCount. The query to compute this might look like:
SELECT
toStartOfDay(CreationDate) AS Day,
quantile(0.999)(Score) AS Score_99th,
avg(CommentCount) AS AvgCommentCount
FROM posts
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
┌─────────────────Day─┬────────Score_99th─┬────AvgCommentCount─┐
1. │ 2024-03-31 00:00:00 │ 5.23700000000008 │ 1.3429811866859624 │
2. │ 2024-03-30 00:00:00 │ 5 │ 1.3097158891616976 │
3. │ 2024-03-29 00:00:00 │ 5.78899999999976 │ 1.2827635327635327 │
4. │ 2024-03-28 00:00:00 │ 7 │ 1.277746158224246 │
5. │ 2024-03-27 00:00:00 │ 5.738999999999578 │ 1.2113264918282023 │
6. │ 2024-03-26 00:00:00 │ 6 │ 1.3097536945812809 │
7. │ 2024-03-25 00:00:00 │ 6 │ 1.2836721018539201 │
8. │ 2024-03-24 00:00:00 │ 5.278999999999996 │ 1.2931667891256429 │
9. │ 2024-03-23 00:00:00 │ 6.253000000000156 │ 1.334061135371179 │
10. │ 2024-03-22 00:00:00 │ 9.310999999999694 │ 1.2388059701492538 │
└─────────────────────┴───────────────────┴────────────────────┘
10 rows in set. Elapsed: 0.113 sec. Processed 59.82 million rows, 777.65 MB (528.48 million rows/s., 6.87 GB/s.)
Peak memory usage: 658.84 MiB.
As before, we can create a materialized view which executes the above query as new posts are inserted into our posts table.
For the purposes of example, and to avoid loading the posts data from S3, we will create a duplicate table posts_null with the same schema as posts. However, this table will not store any data and simply be used by the materialized view when rows are inserted. To prevent storage of data, we can use the Null table engine type.
CREATE TABLE posts_null AS posts ENGINE = Null
The Null table engine is a powerful optimization - think of it as /dev/null. Our materialized view will compute and store our summary statistics when our posts_null table receives rows at insert time - it's just a trigger. However, the raw data will not be stored. While in our case, we probably still want to store the original posts, this approach can be used to compute aggregates while avoiding storage overhead of the raw data.
The materialized view thus becomes:
CREATE MATERIALIZED VIEW post_stats_mv TO post_stats_per_day AS
SELECT toStartOfDay(CreationDate) AS Day,
quantileState(0.999)(Score) AS Score_quantiles,
avgState(CommentCount) AS AvgCommentCount
FROM posts_null
GROUP BY Day
Note how we append the suffix State to the end of our aggregate functions. This ensures the aggregate state of the function is returned instead of the final result. This will contain additional information to allow this partial state to merge with other states. For example, in the case of an average, this will include a count and sum of the column.
Partial aggregation states are necessary to compute correct results. For example, for computing an average, simply averaging the averages of sub-ranges produces incorrect results.
We now create the target table for this view post_stats_per_day which stores these partial aggregate states:
CREATE TABLE post_stats_per_day
(
`Day` Date,
`Score_quantiles` AggregateFunction(quantile(0.999), Int32),
`AvgCommentCount` AggregateFunction(avg, UInt8)
)
ENGINE = AggregatingMergeTree
ORDER BY Day
While earlier the SummingMergeTree was sufficient to store counts, we require a more advanced engine type for other functions: the AggregatingMergeTree.
To ensure ClickHouse knows that aggregate states will be stored, we define the Score_quantiles and AvgCommentCount as the type AggregateFunction, specifying the function source of the partial states and the type of their source columns. Like the SummingMergeTree, rows with the same ORDER BY key value will be merged (Day in the above example).
To populate our post_stats_per_day via our materialized view, we can simply insert all rows from posts into posts_null:
INSERT INTO posts_null SELECT * FROM posts
0 rows in set. Elapsed: 13.329 sec. Processed 119.64 million rows, 76.99 GB (8.98 million rows/s., 5.78 GB/s.)
In production, you would likely attach the materialized view to the
poststable. We have usedposts_nullhere to demonstrate the null table.
Our final query needs to utilize the Merge suffix for our functions (as the columns store partial aggregation states):
SELECT
Day,
quantileMerge(0.999)(Score_quantiles),
avgMerge(AvgCommentCount)
FROM post_stats_per_day
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
Note we use a GROUP BY here instead of using FINAL.
Other applications
The above focuses primarily on using materialized views to incrementally update partial aggregates of data, thus moving the computation from query to insert time. Beyond this common use case, materialized views have a number of other applications.
Filtering and transformation
In some situations, we may wish to only insert a subset of the rows and columns on insertion. In this case, our posts_null table could receive inserts, with a SELECT query filtering rows prior to insertion into the posts table. For example, suppose we wished to transform a Tags column in our posts table. This contains a pipe delimited list of tag names. By converting these into an array, we can more easily aggregate by individual tag values.
We could perform this transformation when running an
INSERT INTO SELECT. The materialized view allows us to encapsulate this logic in ClickHouse DDL and keep ourINSERTsimple, with the transformation applied to any new rows.
Our materialized view for this transformation is shown below:
CREATE MATERIALIZED VIEW posts_mv TO posts AS
SELECT * EXCEPT Tags, arrayFilter(t -> (t != ''), splitByChar('|', Tags)) as Tags FROM posts_null
Lookup table
Users should consider their access patterns when choosing the ClickHouse ordering key with the columns which are frequently used in filter and aggregation clauses being used. This can be restrictive for scenarios where users have more diverse access patterns which cannot be encapsulated in a single set of columns. For example, consider the following comments table:
CREATE TABLE comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY PostId
0 rows in set. Elapsed: 46.357 sec. Processed 90.38 million rows, 11.14 GB (1.95 million rows/s., 240.22 MB/s.)
The ordering key here optimizes the table for queries which filter by PostId.
Suppose a user wishes to filter on a specific UserId and compute their average Score:
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
1. │ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.778 sec. Processed 90.38 million rows, 361.59 MB (116.16 million rows/s., 464.74 MB/s.)
Peak memory usage: 217.08 MiB.
While fast (the data is small for ClickHouse), we can tell this requires a full table scan from the number of rows processed - 90.38 million. For larger datasets, we can use a materialized view to lookup our ordering key values PostId for filtering column UserId. These values can then be used to perform an efficient lookup.
In this example, our materialized view can be very simple, selecting only the PostId and UserId from comments on insert. These results are in turn sent to a table comments_posts_users which is ordered by UserId. We create a null version of the Comments table below and use this to populate our view and comments_posts_users table:
CREATE TABLE comments_posts_users (
PostId UInt32,
UserId Int32
) ENGINE = MergeTree ORDER BY UserId
CREATE TABLE comments_null AS comments
ENGINE = Null
CREATE MATERIALIZED VIEW comments_posts_users_mv TO comments_posts_users AS
SELECT PostId, UserId FROM comments_null
INSERT INTO comments_null SELECT * FROM comments
0 rows in set. Elapsed: 5.163 sec. Processed 90.38 million rows, 17.25 GB (17.51 million rows/s., 3.34 GB/s.)
We can now use this view in a subquery to accelerate our previous query:
SELECT avg(Score)
FROM comments
WHERE PostId IN (
SELECT PostId
FROM comments_posts_users
WHERE UserId = 8592047
) AND UserId = 8592047
┌──────────avg(Score)─┐
1. │ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.012 sec. Processed 88.61 thousand rows, 771.37 KB (7.09 million rows/s., 61.73 MB/s.)
Chaining
Materialized views can be chained, allowing complex workflows to be established. For a practical example, we recommend this blog post.